What is an Application Delivery Network?
What is an Application Delivery Network?  Global Server Load Balancing (GSLB)
Global Server Load Balancing (GSLB)  Measuring Failure
Measuring Failure Network Availability – Is it Important to you?
Alright, we admit that our company has a certain obsession with network availability we collectively call “uptime”. It’s even in our name. We’re totally committed to keeping services up and running for our clients. And while uptime is our best friend, we seem to spend a lot of time thinking about the enemy: downtime. We’ve written a lot about it. Just to remind you, here are a few of the articles we’ve written on the subject:
Leading Causes of Downtime
What Went Down in 2017
Root Cause Analysis to Maintain Uptime
Decrease Downtime with Change Management
Website Down? Understanding Why
So if you’re wondering about all the possible reasons an internet, cloud or other network-based service could fail, you’ll find plenty there to satisfy your curiosity. In this article, we discuss what makes network availability so challenging in the first place: complexity.
Where Is It Down?
The availability of cloud services can be affected by problems at the data center site, such as power and cooling. And while these are areas of concern, the design complexity of these technologies doesn’t match the complexity of the networks that they support. It’s no wonder that redundancy is standard for network elements all throughout the cloud.
It’s no wonder that redundancy is standard for network elements all throughout the cloud.
In May 1844, Samuel F. B. Morse sent the first commercial line telegram from Washington, D.C., to Baltimore, Maryland. He wrote, “What hath God wrought.” On August 16, 1858, President James Buchanan of the U.S. managed to exchange a few messages with Queen Victoria on a new transatlantic cable. But by the middle of September, the line was dead.
Networks are about bridging distances. Merriam-Webster defines telecommunication as “communication at a distance”. When you lose service over a remote connection, the first question on the mind of the technician is: Where is it down? The answer, in the case of the transatlantic cable, was somewhere between America and England.
Dividing the Network – Where is it available now?
In troubleshooting an outage to find out the exact point of failure, sometimes it helps to figure out where the connection or service is not down – or, where is it available now? Back in the 1990s, network engineers in alliances like Global One or MCI Worldcom might check to make sure everything was ok on their own network before sending it to an alliance partner. “It’s ok on my end” means you have no more responsibility except to hand off to your partner and keep the customer informed.
Sometimes you can isolate an issue by checking each point along a connection path. If a signal is supposed to go through five switches but only reaches the third one, then you know that the problem is somewhere between switches three and four. In some respects, it’s similar to the way an electrician might check the wiring of a building for continuity. If you can say “it’s good to here”, then you can direct your attention beyond that point.
Another way that networks are divided is by technological layers. This a more conceptual way to categorize connections and is best represented visually. This diagram from Classmint shows how the seven layers of the OSI model work in theory:
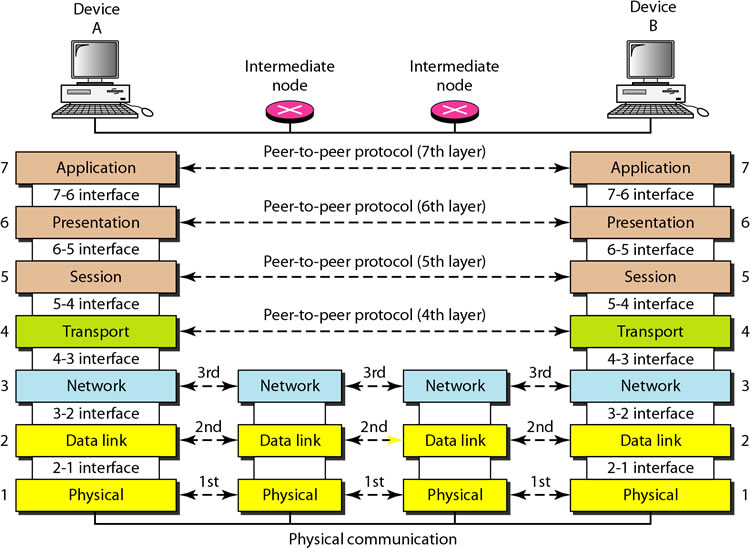
In practice, network engineers know how to check the availability of links for which they are responsible. Someone who looks after layer three, for instance, might check their routers and determine that the problem appears to be at the data link layer. Then they could route the trouble ticket to the department that handles the switches. That’s how things worked in the old days, anyway, as this writer can confirm.
Today, the technologies are even more complex. We seem to have a handle on sending packets over a distance using routers and switches. We’re so good at it, in fact, that much of that old hardware-defined networking is being turned into software-defined networking (SDN). It’s a major transformation of the data center and might even contribute to ensuring higher levels of cloud or network availability, if done well.
A Network of Conversations
As more elements of the network are virtualized and more processes are automated, network designers aim to reduce the need for manual intervention. You might know it as artificial intelligence or machine learning taking the place of network engineers. But for this to work right, the network has to have eyes everywhere. Instead of requiring a NOC technician to troubleshoot the availability of a connection, what if the network diagnosed itself?
For that to happen, the management system would need to have points all along the path that could automatically report back various statistics such as latency, jitter, packet loss, performance and availability periodically. But keep in mind that we are no longer talking about a simple physical connection, as in the case of the telegraph line. Every technology has its own communication stream, and every one of them needs to work.
Take another look at the OSI model diagram above. Across each of those network layers, some kind of protocol is used. And it’s not just one protocol. There are many possible protocols for each layer. To get an idea of the complexity, have a look at this network protocols map sourced from Javvin:
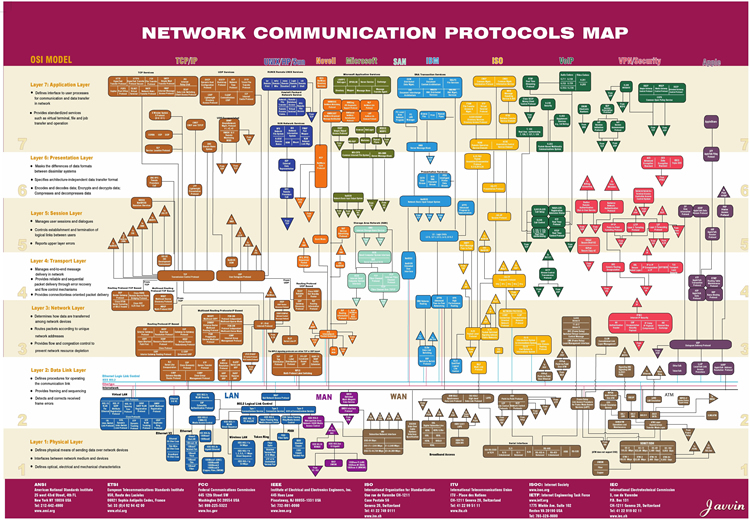
A protocol is a conversation between two computers. The email that you send to your friend is a conversation between your computer and your friend’s computer, often using something like IMAP, SMTP or HTTP. But this is really a stacked conversation, because other protocols are also conversing on the lower layers to make the email possible.
Email is on in layer 7. What happens if the email server goes down? No email, right? But let’s go further. What if your friend sends you a link that requires encrypted Transport Layer Security (TLS) on layer 6? What if there is a Transport Control Protocol (TCP problem on layers 4 and 5? What is there is an Open Shortest Path First (OSPF) routing problem on layer 3? What if you lose 802.11 wireless connectivity on layer 2? What if the power is out, or a cable is cut (layer 1)? There are numerous things to look at when considering what might be causing a network outage.
Now take that email, add in a browser conversation on the HyperText Transfer Protocol (HTTP), a Voice Over IP (VoIP) call, an MP3 audio stream, an MP4 video stream, and more. The network handles all these types of conversations between you and the data center, plus the internet conversations of all your friends and colleagues. How in the world can we ensure the health of all of those services?
Security Affects Availability
The topic of network security is not one that we can cover in a paragraph or two. It’s clear that network hacking by people with bad motives is one of the biggest causes of downtime. The OWASP Top Ten project lists and describes the most critical web application security risks. You can download the 2017 list here.
Any of these threats can bring down your application or connection, instantly altering its availability. For our purposes, we’ll just leave you with the list:
- A1:2017 – Injection
- A2:2017 – Broken Authentication
- A3:2017 – Sensitive Data Exposure
- A4:2017 – XML External Entities (XXE)
- A5:2017 – Broken Access Control
- A6:2017 – Security Misconfiguration
- A7:2017 – Cross-Site Scripting (XSS)
- A8:2017 – Insecure Deserialization
- A9:2017 – Using Components with Known Vulnerabilities
- A10:2017 – Insufficient Logging & Monitoring
The Complexity of the Cloud
What we have discussed to this point deals mostly with traditional networking. The protocols running through switches, routers, load balancers, and other network devices carry digital conversations that are all susceptible to failure. The truth about networking is that there are so many things that could go wrong. That’s why network designers – especially here at Total Uptime – put in so many safeguards to maintain optimal availability. Simply put, network availability will always be at the top of the list. As cloud adoption increases, our reliance on the internet – the network-of-networks – increases exponentially, so ensuring high availability and performance is critical.
The new cloud framework that most companies have now adopted in some form is just as vulnerable.
The new cloud framework that most companies have now adopted in some form is just as vulnerable. But as components become virtualized and applications are moved to nebulous network resources, data owners can lose track of what’s going on, ultimately losing a great deal of control. And what happens if all those cloud resources (compute, network, storage) are overextended or improperly configured? What if the cloud provider goes down and there’s no backup? Sadly, there is a misconception that moving to the cloud increases availability, but this couldn’t be further from the truth as we discussed in our article entitled 4 Cloud Gotchas to Avoid.
Conclusion
Your cloud service or network might go down because of a power problem in the data center. But with the backup power solutions and backup data centers normally in place and with their limited design complexity, it’s less likely that your infrastructure or applications will be affected. Overheating of data center hardware can also take down your service like it took out an Azure data center in September after a lightning strike, but this is rare. Network availability, on the other hand, can be a significant problem.
Things could go wrong on numerous levels. Furthermore, issues with the network can be hard to isolate and they can be especially aggravating when they are intermittent. What we are talking about here is a vast data infrastructure. Network availability is the name of the game.
This is where a company like Total Uptime can really help your organization regain control over the network, even the internet. We specialize at ensuring availability, security and performance at the network level… before traffic gets to the data center or cloud provider. If these things are important to you, contact us to learn more.