
What is it? And how can you implement it?
SHORTCUT: If you just want to get to the part about configuring GSLB in the Total Uptime panel, skip to it here!
Global Server Load Balancing (GSLB) or GEO Load Balancing is in hot demand, perhaps now more than ever before. Placing content as close as possible to those requesting it improves the overall experience and, frankly, is the entire concept behind the “edge” everyone is talking about today.
But the term Global Server Load Balancing is a little misleading. Sometimes “load balancing” isn’t necessary or even desired, but “proximity-based” routing is what you’re really after. For example, consider the basic concept where you have 3 servers around the world. One each in the USA, Europe and APAC and want to send users to the device closest to them. GSLB can do that too!
Sometimes “load balancing” isn’t necessary or even desired, but “proximity-based” routing is what you’re really after.
Total Uptime has been doing GSLB and proximity-based routing for a several years now. In fact, some of our largest clients use our platform very effectively to deliver low-latency content from origins placed all over the world. In a nutshell, Total Uptime gives customers a straightforward control panel to manage how traffic is routed from the end user to any origin device anywhere all behind a single global anycast IP address.
The Basics of GSLB
The general concept behind Global Server Load Balancing has always been to route the user to a content origin closest to them. But it also comes with additional functionality to detect device performance and availability too in order to dynamically adjust that routing in the event of device failure, overload or a number of other parameters.
When GSLB was first designed, it relied on DNS resolution along with end-user IP table lookups to make routing decisions. As users made a request for a particular domain, the GSLB device would use the IP lookup tables to determine the origin device closest to the requesting user and return an IP address in the DNS response based on that lookup.
When GSLB was first designed, it relied on DNS resolution
So, for example, if you were in the USA, your request for www.example.com might result in an IP of 203.0.113.2 being returned, but if you were in Europe your request for www.example.com might result in an IP of 198.51.100.2 being returned. Thus, you would be sent to a server closest to you.
While this concept worked reasonably well and is still the way most of our GSLB competitors and CDN providers route traffic today, this method has three major problems associated with it.
- Giving out the actual IP addresses of devices reveals their location. Thus the GSLB device offers little to no protection to the infrastructure it is responsible for.
- Giving out IP addresses in a DNS response results in caching, making it difficult to redirect the user in the event of failure. In fact, the only way to redirect a user after they have been given an IP is if they perform another DNS lookup so you can give them a different IP.
- User IP addresses aren’t always accurately recorded in IP lookup tables, especially since IPv4 exhaustion has driven inter-RIR transfers. As a result, a user’s IP address may appear to be in one location when it is really located somewhere else. We see this fairly often these days and IP tables are often outdated.
Better GSLB with Anycast
At Total Uptime we carefully deployed a global anycast network to avoid the problems of DNS-based GSLB outlined above. Anycast allows us to use a single global IP address for your application. As a result, if we continue with the example above, when a user requests an IP for www.example.com, regardless of where they are around the world, they receive the same IP address back in response.
The concept behind anycast and the single IP address returned is that it naturally pulls end-user connections to the nearest Point of Presence (POP, a.k.a. data center) because of our highly-balanced network announcements and peering connections. Once the user lands on the nearest POP, you (not DNS) decide exactly where the end-user’s requests are routed based on a number of easily configured parameters in our control panel. Ideally you have devices in at least two locations (otherwise GSLB doesn’t really make sense, right?), but in reality you only need one to simply deploy the concept. You can always add other devices later.
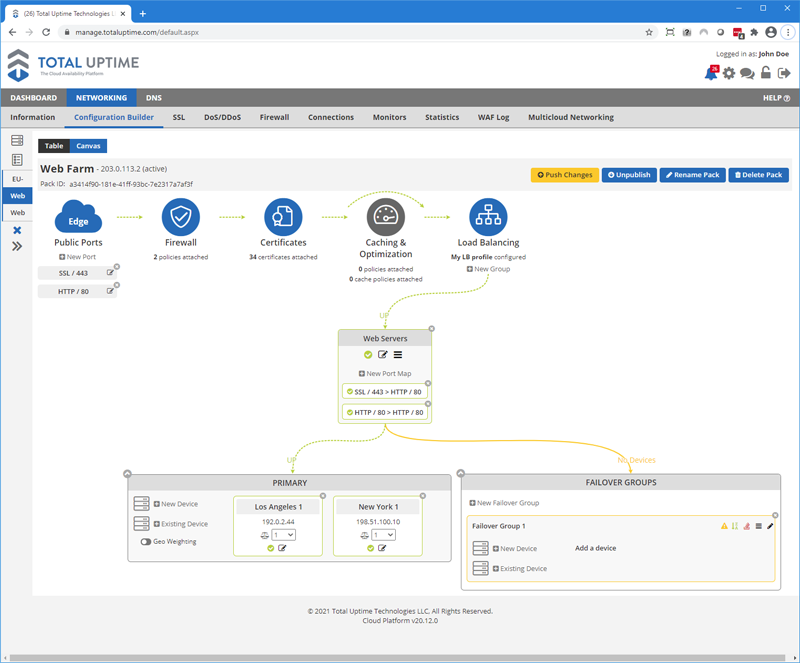
Easy GSLB Configuration
The Total Uptime platform and our control panel makes it extremely easy for customers to deploy geographically distributed devices but place them all behind the same IP address for proximity-based routing to the closest device. We call it GEO Weighting and it is significantly more accurate than traditional GSLB, although we can do that too. In this section we’ll cover the basics of configuring the feature and how you can optimize it for different configurations.
Adding Devices
Just like you would add two devices at one location into a pack for load balancing, you do the same for Geo Weighting. As shown in the screenshot above, you’ll see that we have two devices in the primary group. One in Los Angeles and the other in New York.
Now if you wanted traditional GSLB, no problem. Just click on the Load Balancing icon and choose the “Geographic Proximity” load balance method from the bottom of the list.
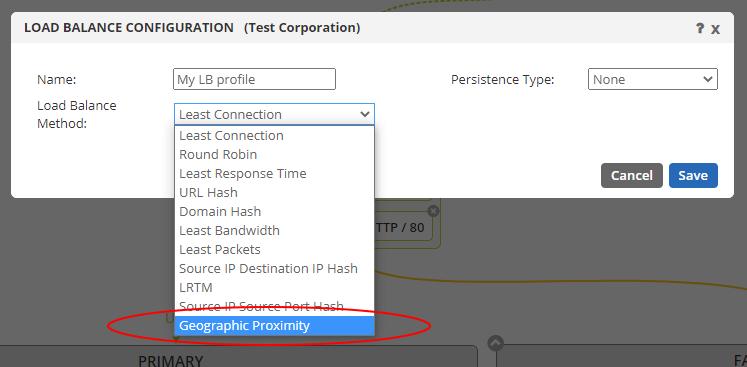
This method is the traditional type. It will consider the IP address of the requesting user and the IP address of the devices in the group and send the user to the one that the IP lookup table and send them to the device that seems closest to them. This feature is included in all of our ADC-as-a-Service plans from PLUS up to PERFORMANCE.
The benefit here is that we don’t give out the IP of your device, we simply route the user to it based on the lookup tables. So unlike traditional Global Server Load Balancing, it still protects your device by shielding it behind our network.
But if you want our very accurate GEO weighted proximity-based routing option, you need our PERFORMANCE ADC-as-a-Service plan. When you have that, you can enable the geo weighting feature (a small toggle) you see inside the primary group, as shown below.

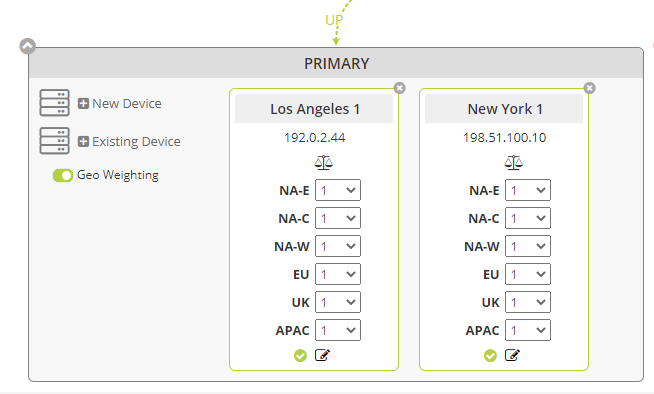
Enable GEO Weighting
Once you toggle GEO Weighting on, you’ll quickly see that the “weight” options for each device within the group expand from one drop-down selector per device to six, as shown below. These descriptors allow you to adjust the weight by region. Each region is further defined as follows:
| NA-E | North America East |
| NA-C | North America Central |
| NA-W | North America West |
| EU | Mainland Europe |
| UK | United Kingdom |
| APAC | Asia Pacific Region |
By default, when you enable Geo Weighting, the weight value is set to “1” for all six regions. We do this to ensure no impact to how traffic is routed to the devices at the outset. But once it is on, you are now in complete control over how to send traffic from each of the six regions to the devices.
In the example below, since Los Angeles is in the NA-W region and New York in the NA-E region, you would weight them to 100 for those respective locations. Since we also do not have other devices configured in our example, you would probably want to weight the UK and EU to send users to the New York device and APAC users over to Los Angeles, since they are geographically closer… at least as packets traverse the internet.
Below is how it would look when rebalanced.
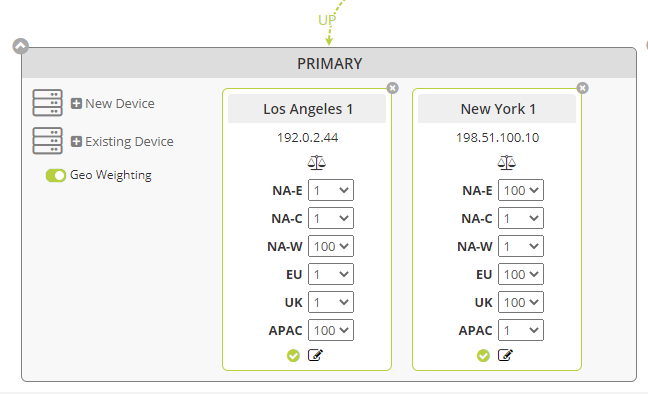
Of course, if you added a device in Europe, the United Kingdom or APAC, you would adjust the weighting accordingly to consider the new device.
The Impact of One
You probably noticed that we left the weights for other regions set to “1”, and for the above scenario it probably makes the most sense. Consider traffic from the NA-C region. If it comes from Dallas, for example, it could easily be served with equal latency by New York or Los Angeles. So in this scenario, traffic from that region would be evenly load balanced between the two with the weight of 1.
If you wanted to weight it more heavily in one direction, you would simply increase the weight value. For example, if you wanted to send NA-C region traffic to Los Angeles for whatever reason, simply increase it to 100. Lastly, regardless of the number, if the value is the same for two devices in the same region, the traffic distribution is the same. 1 and 1 is the same as 60 and 60.
If you really want to understand the weights and how the values from 1 to 100 can be used to carefully balance traffic to different devices, especially if you are load balancing traffic to multiple devices within a single region, we have an in-depth article here that really gets into the weeds.
When Load Balancing is not an Option
Sometimes, you don’t want to load balance, but you still want the proximity-based routing features of GSLB. This might be due to the fact that your devices don’t serve static content, like an e-commerce site for example. Having an end-user flip between regions during a checkout may be something your application isn’t designed to handle.
In such a scenario, you would set the region to a weight of “OFF”. Off means it won’t get any traffic from that region whatsoever. So what is the difference between “1” and “Off”? 1 means it might receive a bit of traffic, but more importantly, it is on standby to receive all of the traffic if the device with a higher weight fails. That can be pretty powerful failover.
When a device is set to OFF, traffic will be routed to the failover group if there are no other devices that have that region enabled.
When a device is set to OFF, it won’t receive any traffic at all and traffic will always be sent to the failover group (if it exists) for that region, even if other devices in the group fail. Because of that, the OFF setting must be used extremely carefully. While it does provide excellent precision for proximity-based routing, it can create a black-hole for traffic if not used carefully.
To combat this, when you select OFF as an option, we will require at least one device in a failover group. Having one (or all) of the same devices in the failover group provides a destination of last resort. As you can imagine, it would be better to send a user from the east coast USA to the west coast USA during an outage of the east coast device vs. sending them down a dead-end street.
Monitoring is Critical for Failover
It should go without saying that monitoring is essential to make failover of any kind work. The platform cannot send traffic to a backup device if it doesn’t understand when the primary device isn’t able to receive it. Even something as simple as a 1-minute ping check is better than nothing. But of course we recommend something a little more reliable than that.
Choosing the right monitor will depend on your application. If it is a web or API server, then perhaps an http GET request is sufficient. If it is a mail server, checking port 25 might be better. You can combine multiple monitors of different types too and set it so they must agree, or that only one will take the device out of service.
You get the idea. Use monitors to reliably determine the availability of your device so the platform can continue serving content to your users even if something goes down. If you want to learn more, we have a good online manual page on monitors to read.
The Best Locations for Proximity-Based Routing
Many clients ask us which AWS, Azure or Google locations are the best to choose for matching up to our regions. After all, the closer your device is to our POPs, the lower the latency and better the performance. So it makes sense to try to locate your origin infrastructure near our regional ingest POPs.
To make it easier, we’ve created a table that references which regions to choose. We have found that devices in these regions are generally 1 or 2 milliseconds away from our infrastructure.
| Total Uptime Region | AWS Region | Azure Region | Google Region |
| US-E | us-east-1 | East US or East US 2 | us-east4 |
| US-C | n/a | South Central US | n/a |
| US-W | us-west-1 | West US | us-west2 |
| UK | eu-west-2 | UK South | europe-west2 |
| EU | eu-central-1 | West Europe | europe-west4 |
| APAC | ap-southeast-1 | Southeast Asia | asia-southeast1 |
Note: We can offer a US-NW region for customers on request.
Of course, if you use other providers like Alibaba, Tencent, VULTR, Digital Ocean and the like, we can help you choose too. Simply let us know who you intend to use and perhaps even provide a test IP for us to check against. We can simplify the process.
That’s about as complicated as Global Server Load Balancing or GEO Load Balancing can get. Hopefully you find that our tools make it easy to accomplish your goal.
Are you ready to implement Global Server Load Balancing or Proximity-Based routing? If you are, contact us for further information or click the Try It Free button below to test drive it now!



