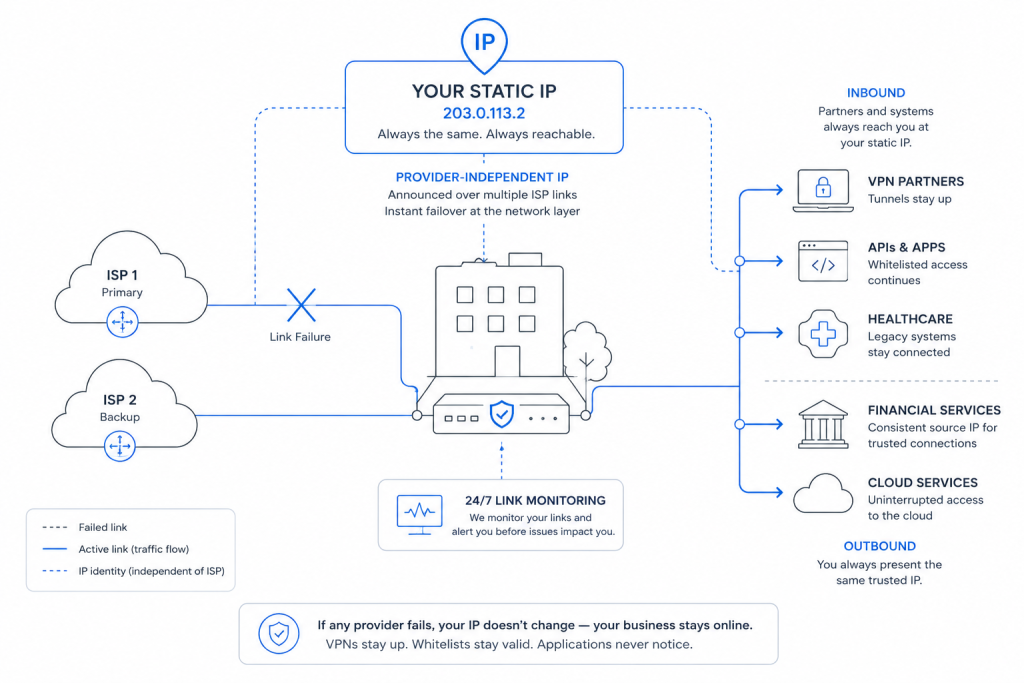
IT systems go down for a lot of reasons. Some downtime causes are obvious, while others take some time to understand. And still others are just plain comical. In this article we’ll have a look at different approaches to assigning blame for outages, and we’ll offer a short list of our own. The concept of downtime applies to so many different arenas in the world of IT, and trying to compare them one-for-one doesn’t always work. Let’s start by having another look at what we mean by downtime.
“The System Is Down”
As we’ve written here before, it’s all about availability. If a particular IT service is not available for use, it would be appropriate to call it “down”. But of course, that’s merely a symptom and not a diagnosis. Information technology has become so complex that intuitively identifying the cause of a problem may be getting more difficult. An experienced network engineer might ask first, “Where is it down? Is the problem on layer 1, layer 2, or layer 3?” But with the changes to IT infrastructure, the OSI model may not be as helpful as it once was.
Many users will never know why their IT service was down.
While the causes of many system outages are eventually identified, many users will never know why their IT service was down. They only see that things are working again, and — if the outage was brief or the application was not critical — they will just go back to their normal business.
The scale or nature of the unavailable IT system can vary. Downtime can be caused by a local problem, such as a software glitch in a workstation, or it can be due to a major event. We might think of downtime in terms of a single application, a website, a network connection, a remote server, a company-wide system, or an entire data center.
Google’s Reliability Engineer
No one is more creative in describing causes of downtime than Luke Stone, the Director of Customer Reliability Engineering at Google. At a session of the 2017 Google Cloud Next conference, Stone gave a talk, now captured on YouTube, on “ten common causes of downtime and how to avoid them”. If you don’t want to take the time to listen to the 50-minute video, you might want to look at a summary of it at TechRepublic. We’ll list them here and make some comments:
- Overload
- Noisy neighbor
- Retry spikes
- Bad dependency
- Scaling boundaries
- Uneven sharding
- Pets
- Bad deployment
- Monitoring gaps
- Failure domains
This is one of the many ways to assess the primary causes of system outages, but you may not recognize all those terms he’s using. The first one is fairly easy: overload is when there is not enough capacity. And it makes sense that multiple retries can lock up a system. But Stone also talks about “shedding the load” and setting limits when their is too much “noise” (i.e., unwanted network traffic). And by “pets”, he means favorite devices, software, or projects that get special attention in various ways. The language that he uses (“queries per second”, for example) applies mostly to Google’s cloud computing environment, but there are lessons there for the rest of us. “Bad deployment”, for instance, is all about failed rollouts.
Application Downtime and FogLogic
The Top 10 list from FogLogic is another example of how there are many ways to approach the same issue. Writer Samantha Larson has gathered these terms as the primary reasons that apps go down:
- Heterogeneous environments
- Multiple single points of failure
- Multiple application interfaces
- Inadequate monitoring
- Resource bottlenecks
- Team Silos
- Job failures
- Network Issues
- Password expiry or locked accounts
- Employee attrition
She seems to be approaching the matter from an organizational perspective. Team silos and employee attrition have to do with the development and maintenance of applications — not with any particular type of events. She admits that her assessment is unscientific, but she believes that these issues contribute to the loss of billions of dollars a year for enterprises.

DILBERT © Scott Adams. Used By permission of ANDREWS MCMEEL SYNDICATION. All rights reserved.
ITIC Survey on Servers
Another way to determine the main reasons for downtime is to ask people. That’s what the Boston research and consulting firm ITIC does. The company Externetworks documents Top 7 Major Causes of IT Downtime based a 2015 survey by ITIC. (We couldn’t locate the original survey results.) The list appears to be about servers, and the terms are quite different from lists above:
- Human Error
- Security Flaws
- Bugs in a Server’s OS
- Understaffed IT Departments
- Outdated hardware
- Instability of server hardware
- Server OS Too Old for New Computers
Are we getting closer to what you thought of as the real causes of downtime? Human error is something we can all relate to. From the person in Hawaii who clicked the wrong button and set off a nuclear panic to the fellow who used imperial instead of metric and cost NASA a Mars probe, we get the idea that humans are perfectly capable of messing up any system. And all the talk about cybersecurity fits with #2 on the list. Most of us can identify with the concrete causes listed here.
Another View on Application Downtime
Nimble Storage is a Hewlett Packard Enterprise Company. In a report that analyzed 12,000 cases of downtime or slow responses, the company came up with 5 causes of downtime:
- Storage – 46%
- Configuration – 28%
- Interoperability – 11%
- Best Practice Errors – 8%
- Host, Compute, VM – 7%
They also say that machine learning and predictive learning can prevent downtime. But why storage? The answer may be in how you define the term. In their paper “Can Machine Learning Prevent Application Downtime?”, Nimble Storage gives this description:
Storage-related issues (46%): These comprise of hardware and software issues, software update assistance and occasionally performance issues. Examples are failed drives (predictive and proactive replacements) and automated software fault analysis with update recommendations.
So software updates and performance issues are batched in with failed drives. One way to define causes of downtime is to create your own definitions.
SolarWinds and Network Downtime
A 2013 blog post in the SolarWinds community forum points to hardware failure as the number one reason for downtime. This seems to align with what most of us think of when there is an outage: Blame it on the hardware. Of course, five years after this post many of the functions once handled by hardware have been virtualized. Nonetheless, their list is worth including here:
- Faults, errors or discards in network devices
- Device configuration changes
- Operational human errors and mismanagement of devices
- Link failure caused due to fiber cable cuts or network congestion
- Power outages
- Server hardware failure
- Security attacks such as denial of service (DoS)
- Failed software and firmware upgrade or patches
- Incompatibility between firmware and hardware device
- Unprecedented natural disasters and ad hoc mishaps on the network such as a minor accidents, or even as unrelated as a rodent chewing through a network line, etc.
Strange Data Center Outages
Hardware problems, human errors, power outages — we all recognize these as common causes of downtime in all forms of IT infrastructure. But what about the less common causes of downtime? The website Data Center Knowledge offers ten of the more interesting causes for data center outages, and these warrant a bit of description:
- The Leap Second Bug. When a single second was added to atomic clocks in 2012, several popular sites went down, and some flights were delayed.
- The Frying Squirrel. One brought down a Santa Clara Data center in 2010, and squirrel-caused outages are more common than one might think. Check out this O’Reilly video called “Frying Squirrels and Unspun Gyros”.
- Servers on the Move. The blog tells how movers took down whole networks when servers were transported to another data center across the country.
- Undersea cable cuts. There were quite a few of them in 2008. Sharks?
- Network Robbers. Thieves cut through a data center wall and stole network cards from a Danish ISP.
- Smoke detected. A data center in Australia shuts down when a smoldering pile of mulch set off smoke detectors.
- Truck accident. Rackspace lost some of the internet’s biggest sites in 2007 after a truck crashed into a power transformer.
- Too much BGP. The configuration of a BGP router by a Czech firm in 2009 caused “a global internet meltdown”.
- Check the pawn shop. Thieves broke into a Chicago data center and stole 20 servers, which they promptly took to a local pawn shop.
Our Unofficial List
We have shown you what many think about the main causes of downtime, but we have not yet run across an authoritative list. Borrowing from these writings and our own experience, here is a brief list of downtime causes we’ve talked about before. Keep in mind that this is not an official declaration from Total Uptime. It’s just another list from this writer.
- Lack of Change Control. The Google engineer touched on it when he talked about “bad deployment”. See our article “Decrease Downtime with Change Management”.
- Poor outage detection and traffic rerouting. Check out “Load Balancing Moves to the Cloud” and other articles on the subject in this blog.
- Lack of proactive maintenance. Here’s another one: “Proactive IT Maintenance to Minimize Downtime”.
- Lack of root cause analysis. To prevent future outages, you need to know what caused them in the past. Read Root Cause Analysis to Maintain Uptime
- Lack of server hardening. Due diligence on server setup and miniatous will prevent downtime. Read this: Server Hardening for Security and Availability
Notice that all of our proposed “causes” of downtime are predicated on inaction. If you really want your IT infrastructure to go down, the best advice is to do nothing. It will eventually go down on its own. That’s the way the universe works. (See the definition for entropy.)
If you really want your IT infrastructure to go down, the best advice is to do nothing.
Conclusion
There are so many ways to look at downtime that it’s difficult to nail down the primary causes in a general sense. The list may be different depending on whether you are talking about servers, websites, applications, the data center, or some other scope of IT infrastructure. The causes are also continually changing. Today there are many causes for downtime in our various computing environments. However you look at it, the main thing to remember is that downtime is bad. Avoid it at all costs.