If you are goal-oriented, you know how important it is to measure success. For network professionals, the goal is usually 99.999% availability (well, 100% in our world). But despite all the counsel we’ve heard about focusing on the positive, sometimes we need to take a closer look at what negative things may affect us. For network management, there are several measures that can help when assessing how well or how poorly a network is functioning.
Mean Time to Repair (MTTR)
Perhaps the most important metric regarding network failure is MTTR. Some part of the network is down. But how long does it take to fix the problem? A few minutes? Hours? Days? Weeks? The customer wants his service back online. If the service is for a VIP customer, then it had better be quick. And if the outage affects a whole lot of customers, then the service provider’s reputation is at stake. Generally, MTTR is measured from the time the service goes down until the moment it is functional again.
Now, we should note that there is some ambiguity surrounding the use of the abbreviation MTTR. BMC Blogs highlights the distinctions in a post on the subject. There are actually four common ways to state MTTR:
- Mean Time to Repair
- Mean Time to Recovery
- Mean Time to Restore
- Mean Time to Respond
The writer’s comments explain further:
Generally, Mean Time to Repair and Mean Time to Restore have definitions similar to those written above [in the article]. Mean Time to Restore is sometimes a variation on Mean Time to Recovery. Mean Time to Respond usually refers to the longest amount of time before your maintenance organization will dispatch someone to look at your issue.
The actual use of the term MTTR, then, is locally defined in the organization. You should also be aware that sometime restoring a service may just mean that an IT professional has found a temporary workaround solution to keep the customer happy until a permanent fix is found.
Mean Time to Failure (MTTF)
Your equipment is bound to fail — eventually. The question is: when? When the HAL 9000 artificial intelligence computer in the movie 2001: A Space Odyssey detected that something was going to go down, he alerted Dave, his human counterpart:
Just a moment… just a moment. I’ve just picked up a fault in the A.E. thirty-five unit. It’s going to go a hundred percent failure within seventy-two hours.
You may not be as precise as HAL, but you can sometimes estimate when you think a particular device might be vulnerable to failure. And you wouldn’t just pull a number out of the air or basing your guess on only one device. MTTF is a calculated number based on the track record of many similar devices over a period of time.
“As a metric, MTTF represents how long a product can reasonably be expected to perform in the field based on specific testing.”
According to Techopedia, “As a metric, MTTF represents how long a product can reasonably be expected to perform in the field based on specific testing.” The term MTTF is generally used to refer to non-repairable items, as opposed to MTBF. Whereas MTTF might be used to quantify reliability of a computer mouse, MTBF might describe an entire system, like a switch or router.
On the other hand, you could think of MTTF as another term for uptime. If 100 devices are monitored for 100 hours, the mean time that is takes for a device to fail could be restated as the mean uptime. It’s just that one is stated in the negative and the other in the positive. (But no one really uses the term mean uptime.)
Mean Time Between Failure (MTBF)
Unlike MTTF, Mean Time Between Failures (MTBF) is focused on equipment that is designed to be repaired and re-used. Weilbull.com, which calls itself a “reliability engineering resource website”, provides us with an interesting article that includes mathematical formulas used to calculate MTTF, MTBF, and other measurements. Weilbull claims that MTTF “excludes the time spent waiting for repair, being repaired, being re-qualified, and other downing events…” But not everyone agrees.
Are MTTF and MTBF used in the same context? Or are they totally distinct because one is used for non-repairable devices (MTTF) and the other is used for repairable devices (network systems)? There seems to be plenty of debate on the differences.
MTTF vs. MTBF vs. MTTR
A discussion of product reliability on the AutomationDirect website uses math that is a little more straightforward. Here they contrast MTTF and MTBF:
MTBF= T/R where T = total time and R = number of failures
MTTF= T/N where T = total time and N = Number of units under test.
Example: Suppose 10 devices are tested for 500 hours. During the test 2 failures occur.
The estimate of the MTBF is:
MTBF= (10*500)/2 = 2,500 hours / failure.
Whereas for MTTF
MTTF= (10*500)/10 = 500 hours / failure.
Perhaps this illustration from Foskets.net will clear things up — or not. The author Stephen claims that MTBF is actually the sum of MTTF and MTTR
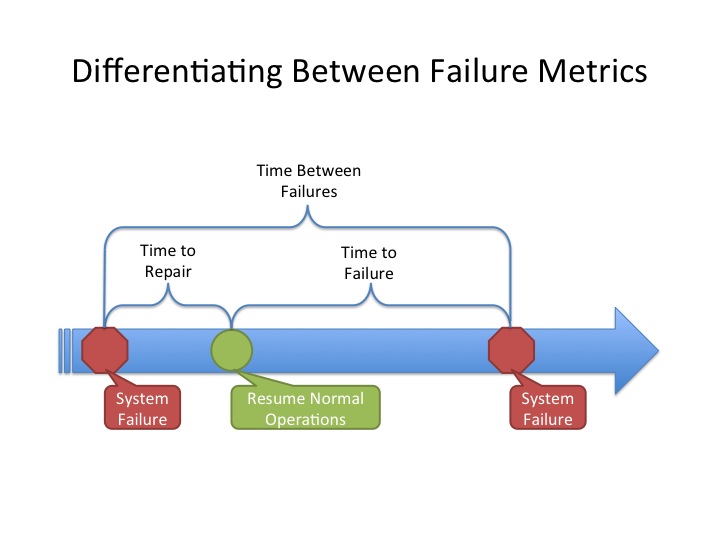
But someone challenged Stephen’s assertions in the comment section:
You know IT but not reliability engineering. The sum of MTTF and MTTR is not MTBF. Mean time to failure (MTTF) is a metric used for non-repairable systems, like light bulbs, that have a useful life and then are discarded when they fail. Mean time between failure (MTBF) is used for repairable systems. It is the average operational time between failures.
It looks like you could get deep into the weeds on these terms and how to define them. We won’t make any official rulings here. Obviously, the exact definitions will vary depending on who is defining the terms. Of course, the important thing is that these terms should be clearly defined in any organization that measures and tracks them. Key performance indicators (KPI) are used in both management and operations to optimize network systems to meet business objectives. Everyone should agree on the terms from the outset.
Other Terms
An organization or industry can have as many terms to describe success or failure that they want, as you might expect. KPI measurements can measure all manner of failures of any kind of device, system, or process that you could imagine. Quality control documentation will define all the terms used in the optimization of networks and systems, and it can all get quite involved. In fact, you could have thousands of these terms with all different parameters.
Some terms are more common in a particular industry. For example, the Business Dictionary defines failure in time (FIT) in this way:
Unit for expressing the expected failure rate of semiconductors and other electronic devices. One FIT equals one failure per billion (109) hours (once in about 114,155 years) and is statistically projected from the results of accelerated test procedures.
Notice here that the term is used in the semiconductor industry. The primary use seems to be for transistors and integrated circuits, but there may be applications in other fields.
Mean time to close (MTTC) is a term that many help desk or network operations center (NOC) technicians will understand. It’s used in trouble ticket management to indicate how long it took from the opening of a ticket until the customer was fully satisfied and the ticket was closed. Ticket management has terms and procedures of its own regarding handling and measuring failures.
Conclusion
It’s clear that properly managing resources and issues is the focus of all this measurement of failures. Managers want to know what’s failing and how often. And then they will want to correlate the failures with particular devices, customers, locations — or whatever will help them to get a handle on the problem. That’s because they want to find a way to predict future problems so that they can then find a way to prevent them. Successes and failures are part of the ups and downs of life. The same goes for every IT system on the planet.