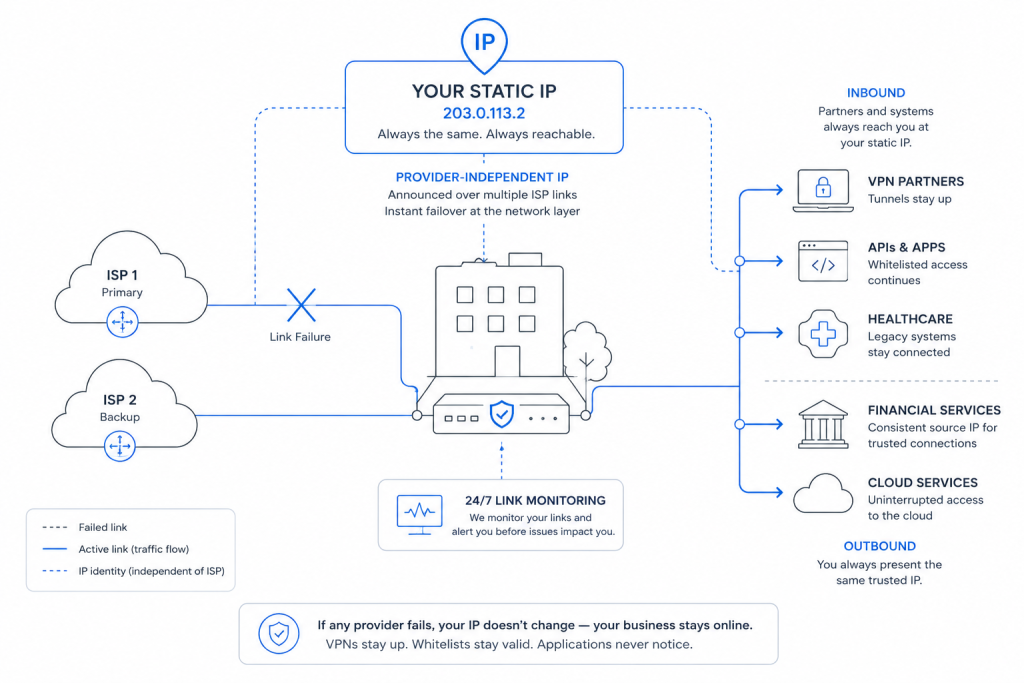
After unabashedly extolling the virtues of redundancy in a recent article , you may be wondering why we would follow up with another post questioning whether sometimes too much (redundancy) was just too much. Credit fellow staffers for the suggestion that we revisit the issue. The problem was clearly a part of our initial research, and it deserves treatment here. So now we ask: Is it possible to have too much redundancy?
Myth or Good Math?
The question was asked on Reddit and the matter is discussed on various boards across the web. Michael Jenkin states unequivocally on the website ARN: “There is no such thing as too much redundancy.” An IT professional has to look out for his clients, he says, and he declares in the title that “too much redundancy is a myth”. But one should be careful when speaking in absolutes, because only one example is required to prove such a statement wrong.
“There is no such thing as too much redundancy.”
A document from NASA, “How Much Redundancy is too Much Redundancy?”, presents the matter as one of diminishing returns. Using mathematical tables to detail estimated reliability and Probability of Failure (PoF), the report concluded that initial efforts at redundancy may be highly successful, while additional measures add little to system reliability. According to their calculations regarding a space communications link, a single redundant line increases reliability by 93%, but additional lines would strengthen redundancy by less than 3%. The more lines are added, the more negligible becomes the system improvement. So would a system with eight redundant communication lines be worth it?
Diminishing returns is one thing. What happens if your redundant solution is actually the cause of system failure? Then you can throw the math out the window.
Simplicity vs. Complexity
Good design is one of the keys to system success, but over engineering can bring it all down in an instant. For a greater understanding of the downsides of redundancy, let’s return to our favorite source on the subject, John Downer’s 2009 paper “When Failure is an Option”. He wrote about the aerospace industry, but many of the same lessons apply to IT. Missing in our initial post about redundancy were the problems that, as Downer put it, “subvert the mathematical ideal of the ‘redundancy paradigm’”.
“Several students of complex systems argue that increasing redundancy can exacerbate complexity to the point where it becomes the primary source of unreliability,”
The first issue to address is complexity. “Several students of complex systems argue that increasing redundancy can exacerbate complexity to the point where it becomes the primary source of unreliability,” writes Downer. He warns of “extra elements” that could deepen the problem. What happens if the management system that you’ve created turns out to be single point of failure itself? Then your risks only increase.
He gives the example of the crash of a twin-engine plane that killed 44 people. When one engine failed, the pilot enacted redundancy procedures. But because the warning system was miswired, the pilot shut down the only remaining working engine, dooming the flight.
Backup solutions in an IT infrastructure may be even more complex than that in active systems. They do no good if they are no more reliable than the primary components themselves. Downer cites the author Mary Kaldor, who said that Russian technology was “uncomplicated, unadorned, unburdened, performing only of what [was] required and no more”. Sometimes simpler is better
Other Factors
It’s not just the complexity of redundancy that can cause problems. Redundant components should function independently. If the backup component behaves exactly the same way as the primary component, will it also fail? A European Space Agency rocket failed in 1996 for just this very reason. When the primary computer could not properly calculate a problem, it promptly passed the problem to the secondary computer and shut itself down. The secondary computer, faced with the same math, also failed in its calculation and shut itself down likewise. The Arianne 5 rocket, with its payload, disintegrated 39 seconds into its flight.
Besides independence, another factor in failed redundancy is propagation. If two engines are better than one, then four must be better than two. But if one engine catastrophically explodes, it can bring down the whole plane. For this reason, Boeing 777 planes were equipped with two engines, thus minimizing the chance of catastrophic failure.
IT redundancy requires independent and robust backup solutions.
IT redundancy requires independent and robust backup solutions. Do you have offsite backup? Will your redundant server go down when your primary one does? As one discussion board participant asked, “if i molotov your server room..will you be ok?”
Conclusion
Redundancy is a critical design factor in many industries, including information technology. Many of the same principles apply across industries. Solutions that are over-engineered, too complex, or lacking independence can be almost as dangerous as no redundancy at all. Charles Perrow highlighted the dilemma in his 1984 book Normal Accidents: Living with High-Risk Technologies. A 2011 article in Nature magazine offers this summary:
“Perrow concluded that the failure at Three Mile Island was a consequence of the system’s immense complexity. Such modern high-risk systems, he realized, were prone to failures however well they were managed. It was inevitable that they would eventually suffer what he termed a ‘normal accident’. Therefore, he suggested, we might do better to contemplate a radical redesign, or if that was not possible, to abandon such technology entirely.”
While we are definitely not advocating here the abandonment of redundancy in IT systems (see our previous article on the subject), we thought it wise to approach the subject from a different angle. Is your redundancy solution too complex? Over-engineered? Not nearly as robust as you had hoped? If so, maybe it’s time to go back to the drawing board. Sorry to break this to you.