
Despite whatever bad news you read in this article, we encourage you to remain positive. It’s just human nature to have a curious interest in the calamities of others. So if that’s what gives you your kicks, feel free to enjoy our 2nd annual dispatch on some of the most interesting outages of the past year. Just don’t forget to keep your spirits up.
January
January 10, 2018 — Major power outage hits CES, a consumer electronics show
“The lights just went out at #CES2018.” Oops! This wasn’t one of those big, widespread catastrophic internet failures that tend to make the news. It just happened to one facility. But it affected a lot of tech companies. “A preliminary assessment indicates that condensation from heavy rainfall caused a flashover on one of the facility’s transformers,” according to a statement from the Consumer Technology Association, organizers of the event. The huge convention, which hosted over 4,000 exhibiting companies, including tech giants like Samsung and Sony, was in the dark for nearly two hours. So much for power redundancy.
February
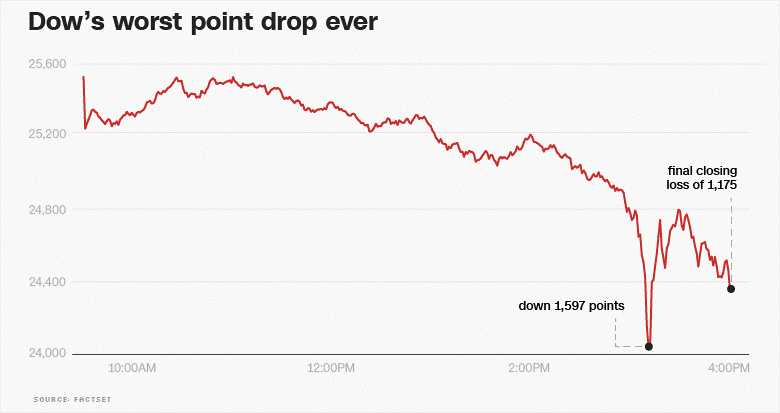
February 2, 2018 — A Tale of Two Trading Sites Told by Network Monitoring
“At 16:30 UTC or 9:30am eastern time, the start of trading hours, this online trading website started experiencing serious drops in HTTP availability for over an hour.” Why? The network just couldn’t handle it. Sure, there may have been some dreaded DDoS attack going on. But it’s more likely that the sheer volume of online trading — part of a huge stock market loss — overwhelmed the servers. Then again, who knows? The author suggests that network intelligence could help discern whether such a problem is an attack or just due to a high volume of user logins.
March
March 1, 2018 — How GitHub Successfully Mitigated a DDoS Attack
Packet loss is not good. And 100% packet loss is catastrophic. That’s what GitHub was seeing in some network paths. ThousandEyes, the network monitoring company that is the source for many of the links in this article, also noticed a problem with BGP reachability. The initial attack only lasted 15 minutes, but it was a follow-up to a DDoS attack on the previous day. The author boasts that the entire detection and mitigation process was likely automatically accomplished by software.
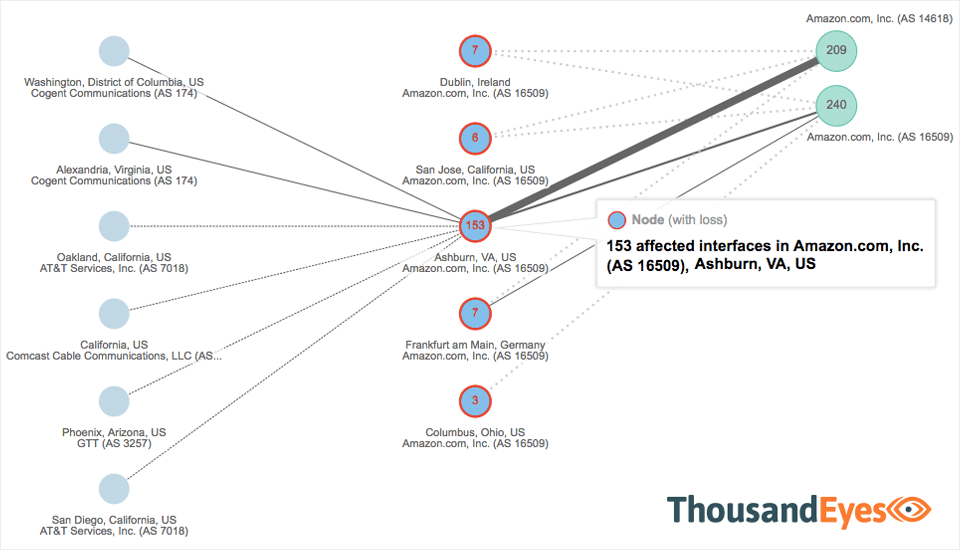
March 2, 2018 — Amazon AWS Outage a Lesson in Managing Cloud First Risks
Don’t you hate it when the power goes out? So does Amazon. Especially when it knocks out key services at its major hub in Ashburn, Virginia. Sound familiar? AWS saw a complete outage of their US-East-1 region one year earlier. We wrote about it in last year’s version of this report, “What Went Down in 2017”. This year’s outage impacted some significant corporate websites. The power problems were short-lived, but they caused serious BGP flapping and service disruption. It was a wake-up call to take another look at the paths and dependencies created in cloud computing.
April
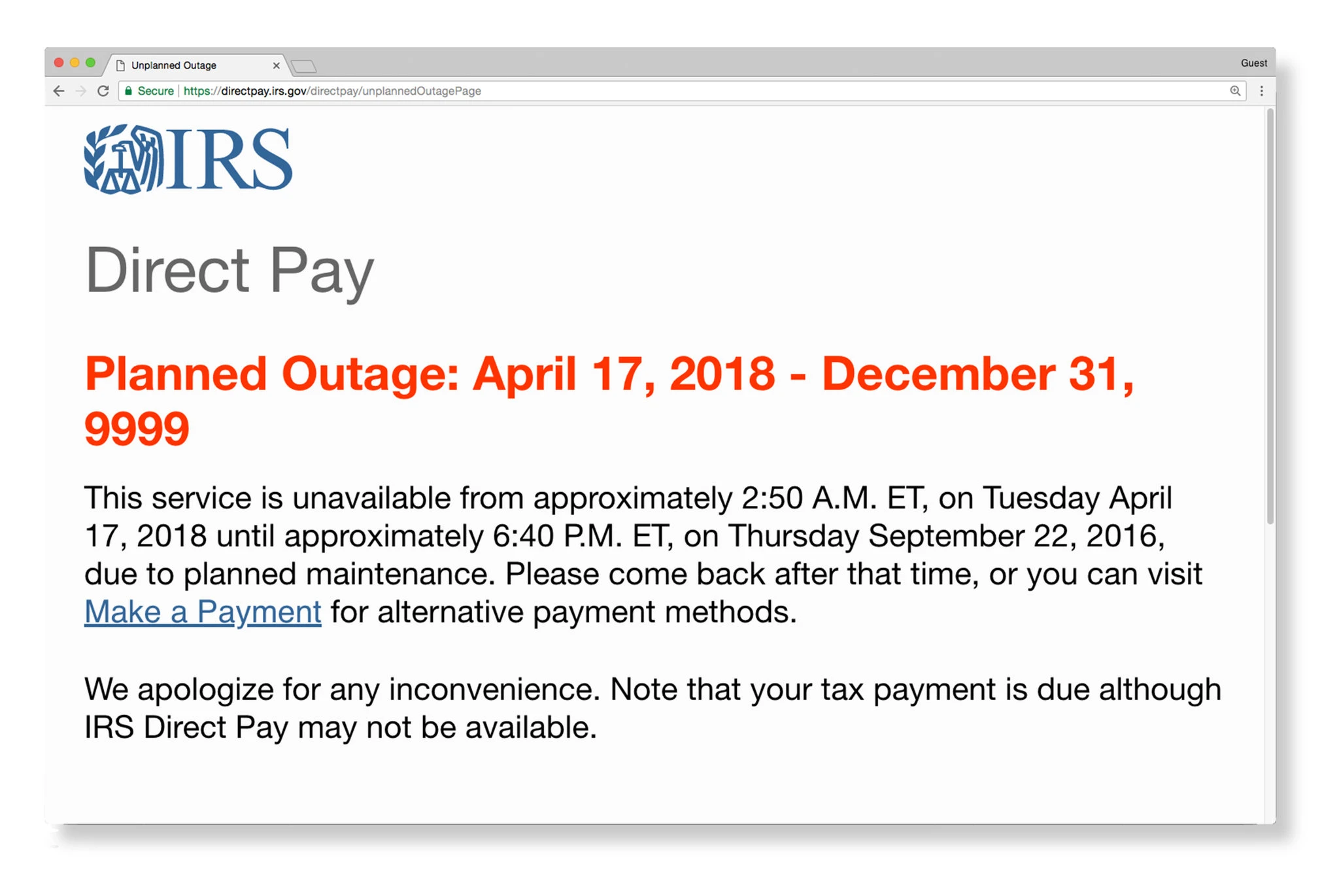
April 17, 2018 — I.R.S. Website Crashes on Tax Day as Millions Try to File Returns
Tax deadlines are important. Missing a due date can result in unwanted fines and aggravations. But what if it’s not your fault? What if the IRS implemented a planned outage on their website on the very day you’re supposed to file? And what if the outage was supposed to run until December 31, 9999? That’s a long outage! Thankfully, the tax collectors finally agreed to give filers an extra day once the site came back up a short time later.
April 24, 2018 — Anatomy of a BGP Hijack on Amazon’s Route 53 DNS Service
There’s an old game of catch where two boys are tossing a baseball to each other and a third boy in the middle tries to lift his glove and snatch it. AWS hackers try this man-in-the-middle game with cryptographic transmissions on Amazon’s DNS service. It happens all the time. Some reports say that this time the hackers got away with $150,000 in cryptocurrency before they were stopped.
May
May 2, 2018 — Network Monitoring to Measure CDN Performance
DNS-based redirection and server selection are optimization techniques employed by Content Delivery Networks (CDNs). The aim is to distribute content to different servers for better geographical distribution. But sometimes these data streams miss their targets. An outage at the cloud service delivery company Fastly was a matter of packet loss. And the funny thing is, data that was meant for the U.S. was being dropped in Japan! (See graphic below.) The author puts it down to “a poorly load balanced network” and “a sub-optimal network path”.
May 21, 2018 — “Slack went down for a few hours today, and it sure was nice”
Slack is an online collaboration portal where work teams can continually remain in contact. A major outage on both U.S. coasts brought mixed reactions. Resorting to social media rather than the Slack “productivity” tool, users voiced either concern or relief. One person posted on Twitter, “Slack is down maybe I can actually get something done and not get distracted”. Another posted a video clip of Homer Simpson wearing a placard that said “THE END IS NEAR”. Mashable blogger Jack had no problem with the outage: “No more inane chatter, no more @here messages — just blissful silence.”
June
June 7, 2018 — A day later, some Comcast phone customers still don’t have service
Most people can tolerate a brief outage of an internet service — but patience wears thin as the outage duration wears on. “Sorry folks! It looks like we are down a second afternoon due to Comcast outages!” tweeted an insurance company. Another Comcast customer posted, “Tough day continues for BusinessWest. Our phones are down again with the Comcast Business outage.” The phone service unavailability affected businesses in Denver, Atlanta, New York, San Francisco, Chicago,, Portland, Houston, Philadelphia, and Seattle.
June 19, 2018 — Visa reveals ‘rare’ datacentre switch fault as root cause of June 2018 outage
We’ve come to depend on our credit and debit cards. Who carries cash anymore? Visa reported to the UK Treasury Select Committee that a “rare defect” in hardware was at the heart of a 10-hour outage. The problem was that a partial failure in the primary core switch didn’t trigger the backup switch to take over. It goes to show that redundancy is not foolproof.
July
July 10, 2018 — Service restored after ‘massive’ outage hits Mediacom subscribers
Cable companies offer a lot more than just cable TV these days. When fiber optic lines in Georgia and Florida were cut, many customers were more concerned about the loss of phone and internet connectivity than missing their favorite cable programs. The incident was referred to as a “massive multi-state outage”. Mediacom had over 1.3 million customers as of the fourth quarter of 2017.
July 17, 2018 — Google Cloud outage brings down Snapchat, Spotify, Discord, and ‘Pokemon Go’
“Something’s not quite right,” tweeted Spotify. Clearly some people were not happy when their favorite apps weren’t working. Imagine what went through the minds of Pokeman Go aficionados when their imaginary world vanished! The outage only lasted an hour, but that’s long enough to disturb and disrupt the lives of some users. The problem had something to do with the Google App Engine, but that’s all we know so far.
August
August 17, 2018 — Microsoft addresses the Office 365 signing and activation issues
It’s all well and good that Office 365 could be “one of the main catalysts of a surprising growth” in the near future. But that will never happen if people can’t log in. Mitigating the impact of an event labelled MO146611 had Microsoft technicians scrambling. Nobody likes troublesome technical issues.
August 21, 2018 — Datacentre issue to blame for Commonwealth Bank outage
It does you know good to have a lot of money in the bank if you can’t get to it. “Some payments in NetBank and CommBank app are not working and we’re sorry for this,” an online notification read. The issue actually had to do with Visa credit card transactions. The Commonwealth Bank of Australia (CBA) advised customers to use other forms of payment “including cash and alternative cards (other than Visa).”
August 30, 2018 — Is Office 365 Down? Users Were Unable To Access Admin Portal
The number of trouble #MO147370 means that Microsoft had 759 issues since their login problem 11 days earlier (see above). That may not be much for such a huge company, but the continued success of Office 365 depends on how well they handle these glitches. “We’re investigating an issue in which users may be unable to sign-in to Office 365 and are receiving an error related to Office 365 subscription activation.” Multiple occurrences of access issues is not a good sign and bad for business.
September
September 25, 2018 — Verizon outage knocks out service across the US
Can’t live without your cell phone? Then you must have been perturbed if this event affected your voice, text, and data capabilities. The “interruption” hit Texas and Florida users hard and lasted most of the afternoon. But the widespread outage spread as far as Chicago and Boston.
September 26, 2018 — Amazon Alexa outage: Digital assistant suffers ‘system issues’
“Alexa…. Alexa!… Alexa?” We can only hope that lonely Amazon Echo users didn’t take it personally when their digital assistant wouldn’t answer them. These systems rely on cloud computing for their intelligence. But make a note. Offline talking speakers dummy up when their link to the collective fails. That makes assimilation that much more difficult.
October
October 3, 2018 — Cisco Webex meltdown caused by script that nuked its host VMs
With the touch of button, you can execute a huge series of commands contained in a script. Such automated wonders can wreak havoc on systems when they’re initiated by mistake. Cisco lost a whole chunk of their Webex platform when an automated script “deleted the virtual machines hosting the service”. The company called the snafu a “process issue”.
October 23, 2018 — Unexpected MySQL database meltdown fingered in GitHub’s 24-hour website wobble
So much for zero downtime. That was the target of CEO Chris Wanstrath, who issued these famous last words to an interviewer: “Our goal is no outages. It’s hard to get to 99.999 but that’s what we are shooting for. Everything we are talking about falls apart if those things aren’t guaranteed.” But bad things do happen, as witnessed by the novel written by Nigerian author Chinua Achebe, Things Fall Apart. Blame it on the data storage system housing the MySQL database servers this time. Oh, well. Maybe next year.
November
November 20, 2018 — LastPass? More like lost pass. Or where the fsck has it gone pass.
Can’t remember all your passwords? Join the club. Or sign up with password manager LastPass, which promises to remember all your passwords for you. Except sometimes they don’t. The author of this article says that connectivity issues are a recurrent theme for LastPass. And the truth is, it’s not really so much that they forget your saved passwords as the fact that a broken link to their servers means you can’t access them. The workaround for this problem is to unlink from the server and use the cached passwords in your app — if you can get that to work.
Everybody seems to be on Facebook now — and we all feel socially compelled to stay there! So what better place for a company’s online advertising? TechCrunch informs us that selling ads is actually how Facebook makes money. Good for them. But the massive outage for advertisers just before the biggest shopping days of the year might make them twice.
It’s easy to make fun of us and laugh at us media buyers expenses bloggers. However, I’m not. Many small biz and, well, my livelihood are dependent on this working. Fbook needs to be help accountable. 28 hours now of a broken ads manager has impacted one biz we work with already.
— David Herrmann (@herrmanndigital) November 21, 2018
December
December 27, 2018 — FCC investigating major CenturyLink outage and 911 disruptions
Losing internet connectivity is obviously inconvenient and puts an internet service provider in a bad light. But losing 911 emergency voice calls for more than a day? That’s “unacceptable” according to FCC chairman Ajit Pai. He immediately announced an investigation. “”When an emergency strikes, it’s critical that Americans are able to use 911 to reach those who can help.” Not only 911, the outage affected such organizations as medical centers, public libraries, ATM machines, and the Idaho Lottery.
Conclusion
The good news is that many of the glitches and snafus and issues and problems highlighted herein will be addressed and corrected so that they won’t happen again next year. The bad news is that many more technical errors will crop up and create nightmares for engineers, managers, and users alike. And yes, people will mess up as much as the machines do. Good ole Murphy’s Law will still be in effect. And while we suspect that networks will be even more intelligent next year, we would have to prognosticate they will never be perfect. That’s a New Year’s prediction that has at least a 99.999% chance of being fulfilled.



